

如何打造优秀的语音交互体验?这儿总结了四个方法
adinnet/2017-09-29 10:28/用户研究

回顾人机交互发展是「技术进步」与「载体创新」交替螺旋促进在推动着人获取信息的效率不断提升,成本不断降低。
AlphaGo先后打败李世石和柯洁,百度发布自动驾驶系统「阿波罗」这一次由AI引领的技术进步正在发生。基于大量纯净数据的深度学习给人工智能带来的了巨大的进步,这种进步主要体现在三个维度。
认知能力 – 基于用户行为的画像,将人机交互从「单向」关系带入「双向关系」。
感知能力 – 由触摸输入到以语音输入、图像识别为核心的全自然交互。
自然语音输出能力 – 带来新的”语音“设计材料。
语音对于体验设计师来说是新的设计材料,它有哪些设计挑战?语音设计有框架可寻吗?有哪些设计方法?我们将在下面的文章与你分享。
二.设计挑战
从「右边界」设计到「无边界」设计
当我们设计App界面,交互设计师会穷举用户在固定像素界面内所有可能的操作,一一设计恰到好处的用户反馈。但是对于语音交互用户的输入是没有边界的,用户可能的输入将远远超出你可能的穷举的范围。从「有形」的设计到「无形」的设计,视觉的设计规范在语音设计过程中将完全失效。
从「进场」交互到「多距离空间」交互
语音交互主要分为近场交互(例如:度秘/Siri)和中场交互(车载)、远场交互(智能音箱)。

多距离场景的有以下几个维度的不同:
(1)场景特征:在非近场交互的场景下用户可能在其他事情上,而非专注在其他任务,这给如何让用户更小成本的获取当前系统的状态带来挑战,「我唤醒了设备吗」「我们可以说了吗」 每一个节点需求都需要多维度的定义。
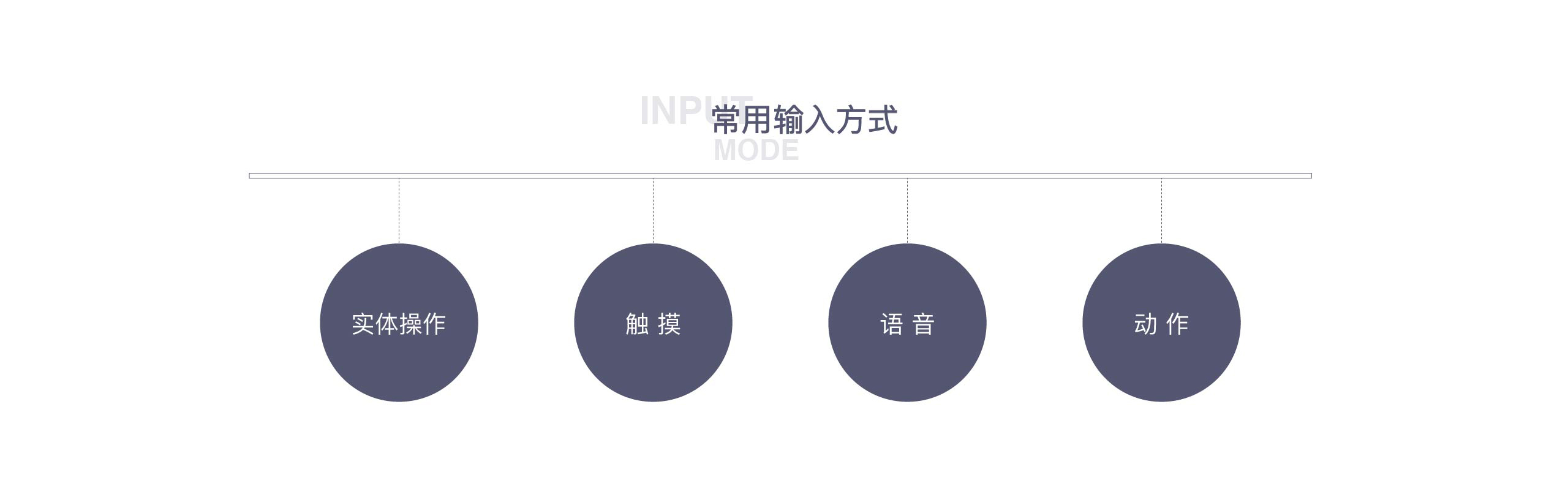
(2) 输入方式:常用的输入方式有实体操作(按钮/旋钮等等),触摸,语音,动作,在近场交互时实体与触控是第一选择,而当中远场交互时语音成为输入方式的第一选择。伴随各种智能音箱、或者Iphone X等采用深度摄像头应用的普及,中远场景的动作输入将逐渐成为重要的输入方式之一。
三. 设计建议
用「语音交互框架」匹配「使用场景」
语音交互带来人机交互向更自然的方向提升,人机交互更趋近于「人人交互」,怎样理解语音交互框架,我们可以从人人交互一探究竟。
现在回想你让别人帮你把水杯拿过来,你与这个人的交互节点是什么样子的?
首先你要叫他的名字,如果他听到了会回答你「干嘛呀」或给你个眼神儿,这时候你知道他在听你说话,你可以继续说了「把水杯拿来」。他可能需要想想水杯在哪或者问你,当他去拿水杯你会看到他正在行动。将与人的语音交互节点提炼出来,进行总结就是语音的交互框架:

如上图所示语音的交互框架由以下四个节点构成,每个节点用户有相应需求:
唤醒:用户有得到「是否唤醒语音」反馈的需求
输入:用户有得到设备正在「听说话吗」的需求(相当于loading)
理解:用户有得到「在帮我说事情吗」 的需求
回答/行动:用户有查看任务是否完成的需求
语音的交互框架解释了语音交互流程,等同于触屏设备定义的「点击屏幕」「双指Pinch」「摇一摇」。但是仅仅了解交互框架是远远不够的,比框架更重要的是语音交互场景,在不同场景下以上「唤醒、输入、理解、回答/行动」四个节点有不同设计方式。
举个例子:在语音交互的第二个节点 – 输入中需要用「波形高低」与「语音响度高度」相匹配来给用户正在聆听的反馈,在不同场景下波形要采取不同的设计策略:
车载场景:驾车时用户的视觉注意力被路况占据,这时候一方面需要引入「叮」的一声语音反馈,另一方面需要设计采取更强的视觉波形确保一瞥既得。
语音音箱:语音音箱的场景虽然不像驾车场景注意力被强占据,但是它是没有屏幕的,这时候一般会采取带强弱有呼吸感的灯效解决反馈的问题。
「无形」的语音能「附着」在各种设备上,场景也是千变万化的。在设计时要时刻记住「唤醒-输入-理解-回答/行动」的语音交互框架和每个节点的用户需求,关注用户的使用环境,和视觉/听觉注意力的占据情况,不要局限只用声音做反馈。
唤醒设计
唤醒是语音交互的第一步,听说刚发布的某国产品牌的AI音箱选了十多个唤醒词,更后才用了「小爱同学」,Rokid的唤醒词「若琪」也经过了精心的设计。这充分说明了唤醒设计重要性。
唤醒方式可以是任务的触发动作,比如点击,按压,动作,语音,表情。目前主流的唤醒方式有以下3三种 – 实体按钮、虚拟按钮、语音唤醒,每种唤醒方式各有特点,适用于不同场景,下面我们来逐一分析一下:
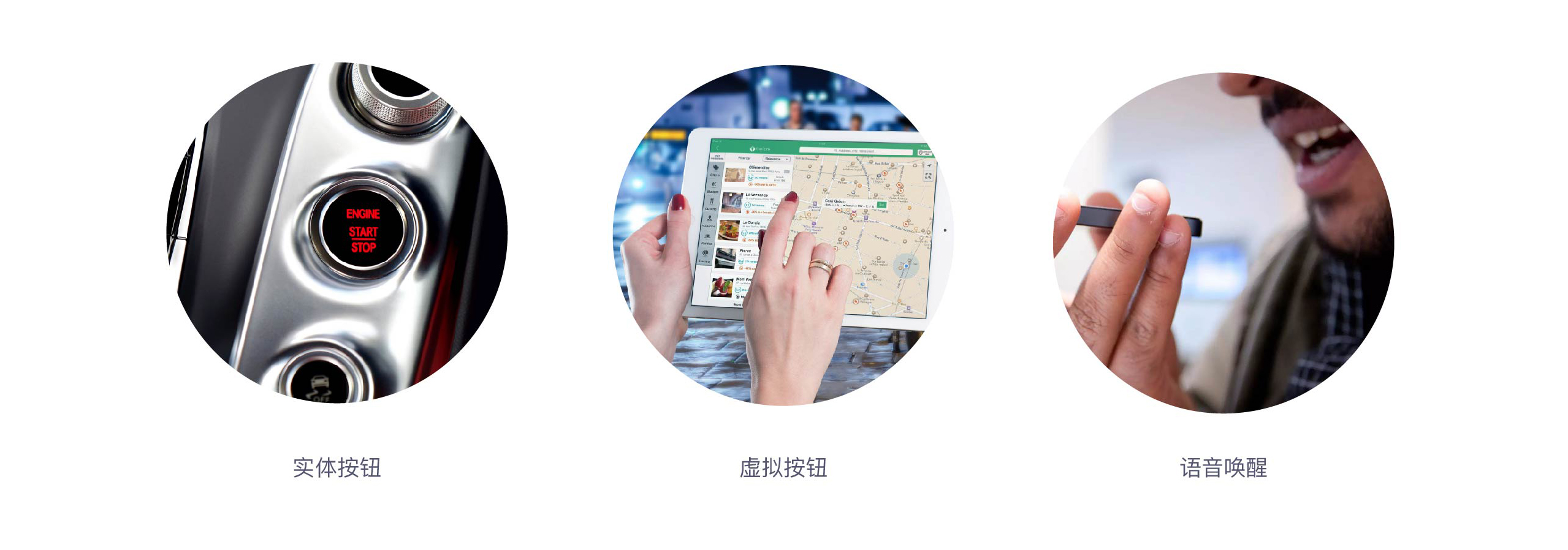
(1) 实体按钮:优点是能提供触觉反馈,使用场景有两种:
A.当用户的视觉通道被占据时。
B.近场交互且设备没有屏幕或屏幕处于熄灭状态时,例如在熄屏状态下通过长按Home唤醒。
(2)虚拟按钮:唤醒方式有两种操作方式 – 点击和长按。两种方式的本质差别有三个:与面部距离、操作成本长按大于点击、微信养成的语音输入习惯使得长按更符合用户习惯。
A.点击:面部与屏幕距离远,波形反馈可见,能更好的确认设备是否在收音,且成本较小。大多数的近场交互都可以使用。同时车载场景特别适用,试想在驾车情况下让用户长按输入语音简直就是灾难。
B.长按:离麦克风距离比较近,能带来更好的收音效果。可以作为一种辅助的唤醒方式兼容。
(3)语音唤醒:在双手被占据和远距离场景下语音唤醒都是更佳的方式,在设计语音唤醒时要注意以下三个方面:唤醒词的形象设计、注意唤醒后的声音反馈、防止误触发。
A.唤醒词的形象设计:唤醒词的设计是机器人格的一部分。在平常的社会交往中,高雅、深邃的名字,往往会给人留下美好的印象。庸名俗字则给人一种不愉快的厌恶心理或排斥感。比如「静静」给人「文琪、秀气」的感觉。「糖果」给人「甜蜜」的感觉。
初期的人工智能的能力是有限的,有时会给出不尽如人意的回答。一个萌萌的有亲和力的名字能让用户有更高的宽容度。
同时唤醒词意象要与声音特色相一致,听觉情感是非常敏感的,想象一下如果一个萌妹子说话的声音很粗犷,或者一个壮汉声音很细你是不是觉得很不舒服。去定义唤醒词对应的感知意向,在语音合成训练时匹配这种意向。
B.使用反馈音:语音唤醒一般使用在远场交互场景,这时候用户很难能通过视觉确认是否唤醒了设备,就需要给出语音反馈。比如「叮」或「我在呢」等等。
C.防止误触发:在日常交流中我们每天会说很多重复的字或词,比如「你、哎、哦」等等,在设计唤醒词时要避开这些词汇。
对话的体验设计
唤醒之后的对话环节是语音体验设计的核心,我们如何打造优秀的设计体验呢?首先需要了解语音交互类产品对话的基本特点,包括:轮流说话的方式、合作式的对话、关注语言的蕴意及语境、具有线索引导、对话具有可修复性。
在具体对话的编写上,给大家推荐通用的Grice表达准则,可以有效提升语音对话的效果。准则包括以下4方面:
表达质量:陈述的是有效的事物
信息量:不多不少,恰到好处的语言信息含量
关联性:陈述与话题相关的信息
习惯性:简明扼要,直奔主题,避免模糊晦涩的表达
根据不同的使用场景对话编写也有较大差别,主要从以下两个维度入手:
(1)区分「任务式设计」与「闲聊式设计」。对话式设计主要分为两种场景:任务式对话和闲聊式对话。
任务式对话:如理财顾问,医生,购房助手,用户使用这类对话的型产品是为了尽快得到答案,而不是向人们「调戏」siri一样。这类的产品应遵循如下原则:
A. 引导用户如何输入
语音是无形没有边界的,不要让用户进来不知道说什么。用户可能采用各种无法预知的句子输入。为了避免发生错误,应在界面上引导用户怎样输入或主动开启一个对话。
B.设置边界
不要试图去做闲聊型「机器人」,当入用户的输入你的产品无法理解或与你产品的主任务无关时,不要装聪明,给用户选项提醒用户他能用的表达方式。
闲聊式对话:如微软小冰,度秘等。用户使用这类对话式产品的目的是「娱乐」,效率不在是第一需求,怎样让对话有趣避免冷场是新的设计目标:
A. 双向沟通,主动联想
避免对话一直是「one shot」式的一问一答。双向的沟通才能让对话变得有趣,当用户打开你的产品时根据天气,时间等因素做主动的交谈,比如当用户深夜打开你的产品时,设置一段问候的对话会让你的产品变得富有人文关怀。
B. 迎合用户情绪
当用户表达出悲伤或开心等情绪时,用户会很期待你的产品具有同理心,用图像或对话与用户建立情感连接,将使得对话变得富有人情味,增加产品的粘性。
C .鼓励输入
闲聊式对话产品的体验依赖于对用户数据的收集,你的产品积累的对话数据越多,通过深度学习就越能给出用户满意的反馈。在设计时通过奖励机制和可视化的鼓励引导用户来丰富你的数据库。
(2) 「听觉形象」的体验设计
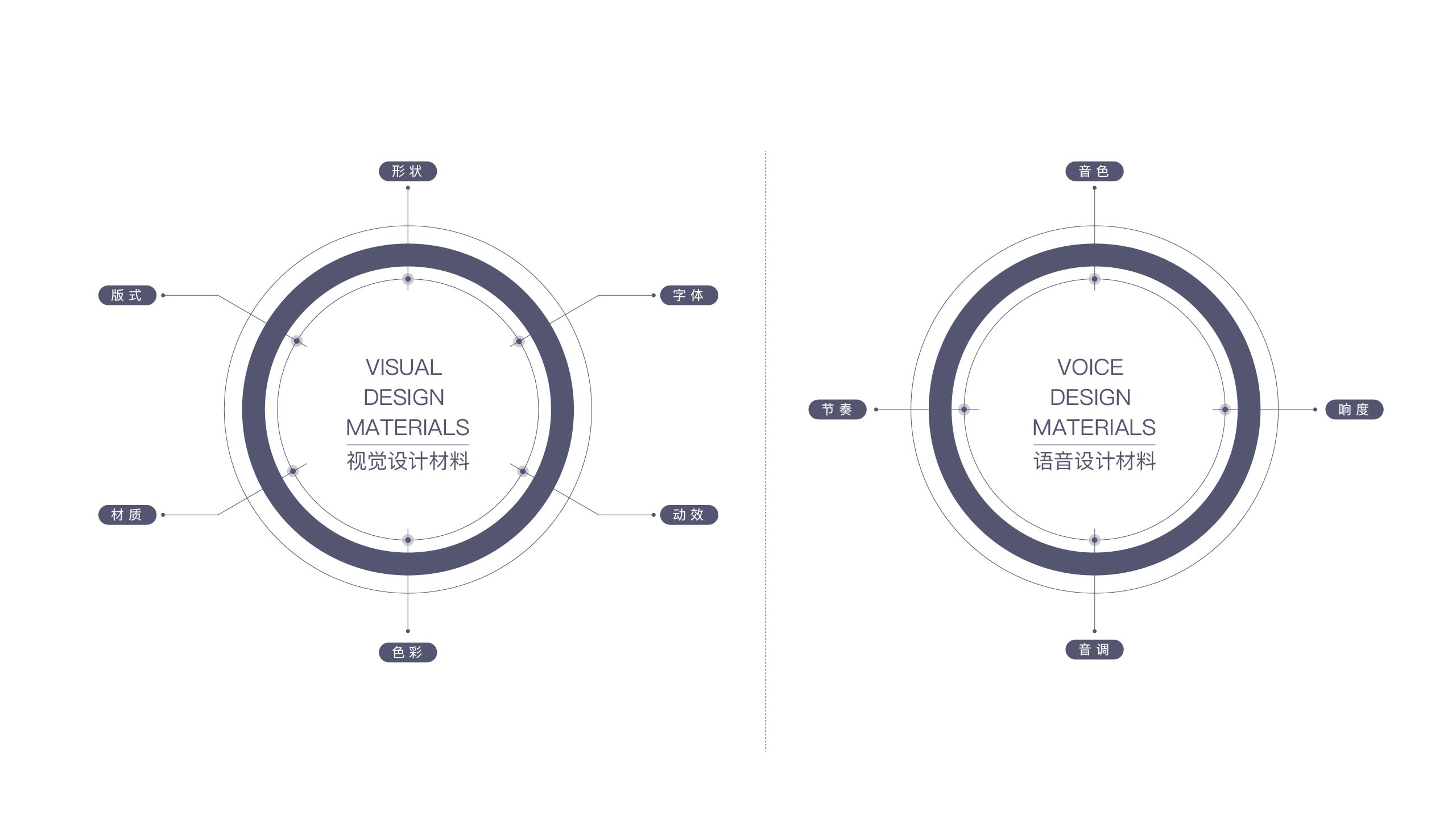
通过「彩、材质、形状、版式、动效、字体」塑造视觉形象,用视觉形象反映产品气质、品牌理念是GUI设计师工作之一。人工智能赋予了机器拟人化声音输出的能力,带来的语音设计材料。不同的声音带给用户的感受是不大相同的,低沉的声音给人「稳重、沉稳」的感觉,尾音语调向上的声音给人「愉悦、被尊重」的感觉。
如何用「音色、节奏、音调、响度」的语音设计要素设计恰如其分的听觉形象?
下面我结合项目经验和一些研究与你分享一些流程的方法。
A.从「先设计后开发」到「先开发后设计」一个全新的实现流程
语音是不可见的,设计师没有「语音的PS」 ,在语音形象的设计中必须先有「语音基础形象」设计师基于语音基础形象进行再设计。对百度feed读新闻的体验重新设计时,先进行的是不同新闻情感特色的定义,基于新闻情感收集当量的「语料」数据,通过深度学习来提取每类语料数据的声音特色形成「基础形象」,在对基础形象进行「语调、速度、节奏」的微调进行升级形象设计。
以上流程可抽象出「听觉形象」的设计流程 :「定义 – 挑选 – 训练 – 调整」。

定义:根据内容/产品气质/品牌愿景定义产品的「听觉形象」,八卦的情感要用「戏谑的」,历史的听觉相应要有「沧桑感」。
挑选:去语音库里挑选具有定义的听觉形象的语音片段。比如如果要产生的听觉形象是「沧桑感」时,可以挑选一些单田芳老师语音片段。

训练:将大量语音片段交由技术人员进行语音合成训练。
微调:通过调整「语调、速度、节奏」使之给用户的感觉更接近于先前定义的「听觉形象」。
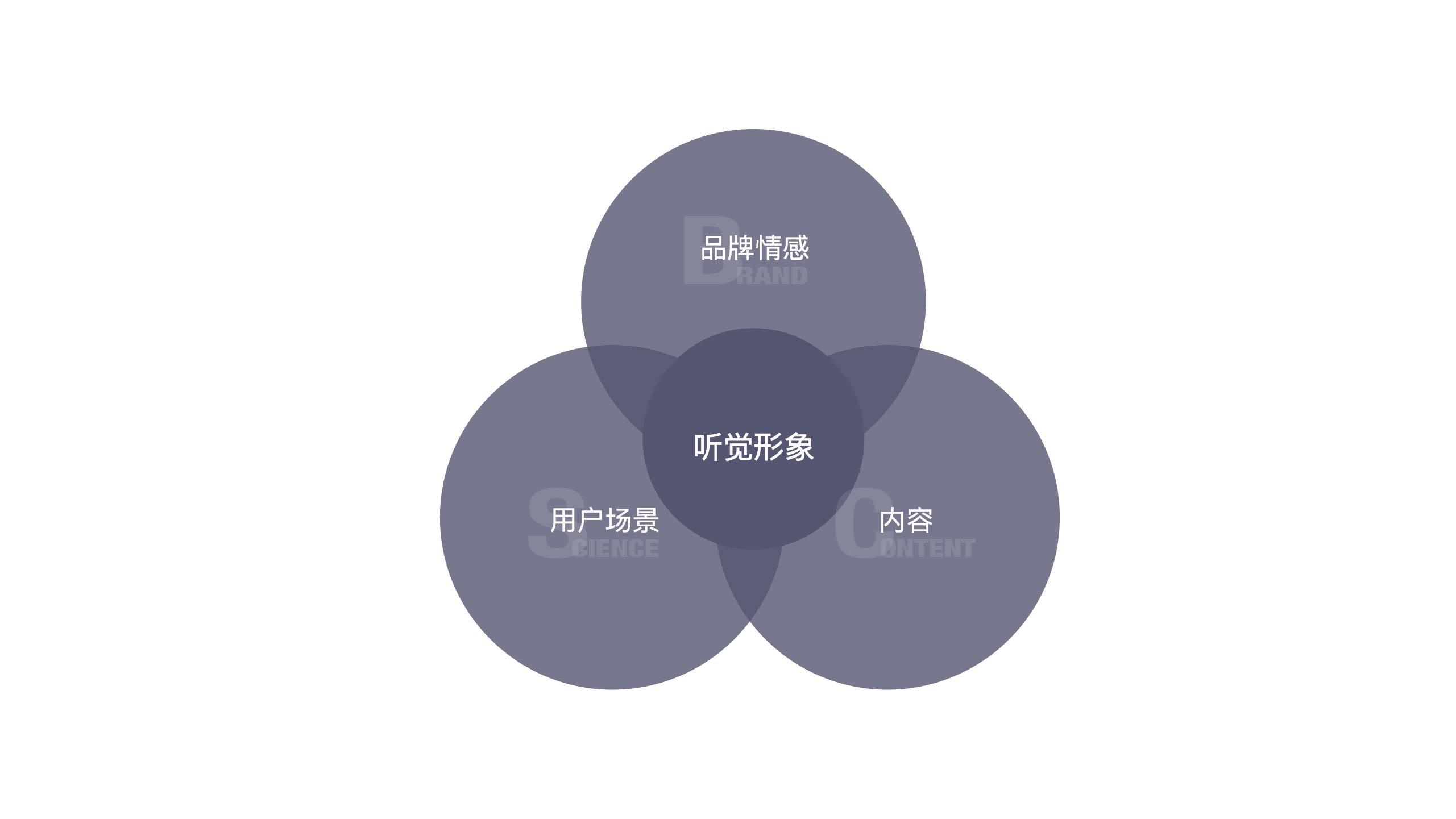
B. 保持「听觉形象」与「品牌情感」的一致性
在进行视觉设计时设计师要通过「色彩、形状」等设计元素支撑品牌情感,对与大型公司会要求他们的每一个产品遵循一致性的设计规范。进入「听觉形象」设计时代,当你的产品要使用语音交互时,确保产品的「听觉形象」与「品牌情感」保持一致,这将能够强化品牌给用户的印象。
C. 保持「听觉形象」与「用户场景」的一致性
现在回想一下机场内的语音「尊敬的旅客飞往北京的T343航班….」,这种语音形象给用户「被服务的、受到尊敬」的感觉,与用户在机场的场景相一致。而在医院,起码在中国的医院,医疗资源与患者数量极不匹配,患者与医生更像是「求助关系」而非「服务关系」, 使用过于「服务化」的语音形象反而会给用户带来强烈的落差感。
D. 保持「听觉形象」与「内容」一致性
「内容」本身是具有形象属性的,比如二次元的新闻如果用粗犷的男生读出来一定会很违和。因此在进行内容消费型设计时要充分考量语音所说的内容与「听觉形象」相匹配,避免出现违和感。但是在设计工具型产品时,不要频繁更换语音形象,这会分散用户注意力使效率下降。
4.利用视觉
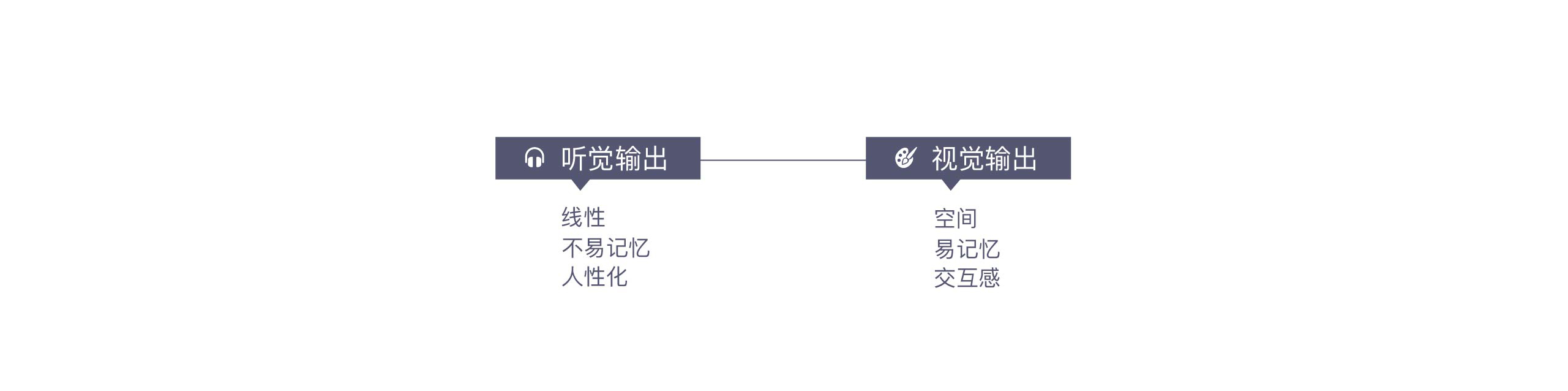
语音交互的更大优势是更加直觉化,可以大大降低用户学习成本。但是语音输出的是线性的,因此它无法同时输出很多内容。这是语音更大的劣势。
2015年在设计语音管家时有人提出要做个语音点外卖功能。这其实是违背语音场景的,当语音输出到第十道菜时用户已经忘了第一道菜是什么了。 所以当时在设计时当用户发起需要当量信息交互的任务时,会通过PUSH引导用户查看视觉信息。
在设计时充分利用视觉与听觉的互补性,听觉记忆时间短暂的,不要用语音输出大量信息,尤其输出的信息是需要用户记忆时。
四. AI时代的变与不变
AI带来机器的认知能力和感知能力的提升,给人机交互带来的改变是根本的,传统的人机「输入-反馈」循环,将逐步过渡到「推荐-选择」循环。人机交互也将由单向从属关系,向双向训练关系过渡。这种改变将重写「设计思维、方法、流程、规范」。
然而每个时代都会有属于它的符号和偶像,对于设计师来说,赋予产品以灵魂的精神是始终不变的。
本文转自:http://www.uisdc.com/make-excellent-voice-interaction
