

亚马逊语音交互设计规范(二)用户说的内容
adinnet/2017-12-29 10:12/用户研究

编者按:在上期的文章中我们主要了解亚马逊语音交互设计规范以及对话交互的设计流程。接下来,我们将继续学习亚马逊语音交互规范的内容——如何让Alexa了解人们在说什么。
上期回顾:《亚马逊语音交互设计规范(一)设计流程》
人与人之间的交流就是在当前背景下交换意义。 表达和提取意义并不像看起来那么简单,我们需要仔细的设计Alexa和用户之间的对话。 一个好的语音交互体验应该能够让人们尽可能多样的表达意义和意图。
对话UI由一个人说出话题开始,接着Alexa回应。 这对许多人来说是一种新的互动形式,所以需要确保了解用户参与会话的方式,以便我们可以更好的设计。
本章内容:
1. 在搭建对话之前完成设计
2. 识别意图
3. 使用内置的意图
4. 识别话语
5. 处理过度回答
6. 处理用户的更正
7. 涵盖多样话语
8. 识别词槽
9. 仔细检查词槽值
在搭建对话之前完成设计
思考我们想要人们使用功能时体验和感受到什么。 一旦确定了功能,写完了脚本和布局流程的目的,我们就能开始设计意图和话语。
识别意图
意图(Intents)代表用户可以通过技能来做什么。技能可能有助于计划旅行,获得状态,说笑话或攻击怪物,这些都是意图。有关确定意图的技巧的指导,请参阅第一章《设计流程》。
不要假设人们会准确的说出预期的意图对话。用户可能会说「计划旅行」,他也会说「计划去夏威夷的度假」。为了确保功能表现良好,我们需要提供各种各样用户可能会说的句子、短语和词语。
以下是用户可能会表达「计划我的旅行」的几种方式:
我想去旅行
让我们开始计划旅行
计划旅行
我需要休假

使用内置的意图
每个Alexa技能都需要包括取消,停止和提供帮助的功能。对于这些和一些其他常见的意图,比如重复,播放和下一个,请使用内置的意图库。已经内置了意图库的话,Alexa就可以识别相应的话语。例如,根据内置帮助意图,就不需要再详细说明一个人可能要求帮助的方式。如果技能需要对人们可能会说的其他事情做出反应,我们还可以扩展内置意图。
识别话语
话语(utterance)是一个人对Alexa说的话。话语(Utterances)由关键字命令,自然语音(如填充词)和用于不同信息的词槽组成。设计语音交互体验一个更重要的方面,就是确定人们可能会说的话的范围。
为了帮助确保良好的体验,需要提供各种完整的,不完整以及不明确缺损的例子。为确保覆盖范围,甚至还需要包括微妙的变化和错误发音。例如,即使「arrangement」和 「bouquet」有相似的含义,在谈论「花」时也需要包括它们。
原文:For example, include “arrangement” and “bouquet” when talking about flowers even though they have similar meanings.
1. 一次性对话
一次性对话是指一句话就能够包含激活意图所需的所有内容。它们可能出现在唤醒技能的开头,也可能出现在功能使用的过程中。

2. 信息缺失
用户经常提供命令或请求时,包含一组不完整的可变信息。这就需要多回合对话来收集其余的信息。

处理用户的过度回答
有时候即使Alexa只要求一个回答,用户也可能提供多个答案。比如Alexa提示需要出发日期,用户也许会提供日期和出发城市。甚至用户会提供其他需要的信息,如抵达城市和活动,而不是提供Alexa要求的日期。
处理这种情况对于对话设计也很重要。可以在亚马逊官网发布的对话框界面参考和计划我的旅程教程中了解更多信息。
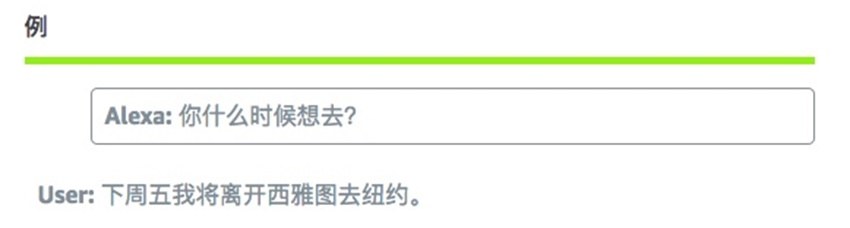
处理用户的更正
当用户觉得Alexa的回答有问题或改变想法的时候,他们会进行更正。例如,用户可能会说「不」或「我说的是」,后面接着有效的话语。我们需要对这种情况提供处理机制。

涵盖多样的对话内容
为了确保功能表现的不错,一个基准是即使是很简单的意图,每个意图也需要30或更多的对话单元。我们不需要100%的覆盖,但越多的例子功能会表现的更好。此外,需要持续添加话语以优化技能表现。
1. 创造不同话语的提示
如果用户说「我打算去旅行」,Alexa就需要收集目的地城市,到达城市,旅游日期和活动。我们可以试着让家人或朋友一起来试试表达方式,以便我们可以模拟用户的多样对话。
2. 一次性对话
试想一下用户可能会在一个话语中说出所有词槽的方式。

3. 部分信息变体
我们需要想用户可能会给出信息的多种常见方式。这点非常重要,因为人们不可能一次性地说出我们需要的一切。

识别词槽
词槽是人们指定话语的可变部分,例如城市或日期。词槽在以任务和信息为主的技能上很常见。我们可以设计词槽在话语中的展示方式,然后从内置目录中选择词槽值,或提供自己的词槽值。
在下面的例子中,话题,「toCity」和「travelDate」是词槽:
我想去「toCity」
预订「travelDate」之旅
计划去「toCity」度假
使用内置词槽值
尽可能使用内置词槽值,以节省时间和提高准确性。根据技能,我们还可以扩展一些内置值。例如,对于本地区域,我们可以扩展AMAZON.US_CITY以包括所有本地城市和城镇。有关更多信息,请参阅可扩展的词槽值。
仔细检查词槽值
虽然可能很容易找到或复制和粘贴单词列表来填充词槽值,但请确保查看并编辑内容。错误的词槽值会造成功能的逻辑错误并破坏用户体验。查看以下:
重复词槽值:确保消除重复的值。
字与词槽无关:避免包含与词槽无关的单词。
拼写错误或不正确的标点符号:对于包括引号值,例如「child’s play」,请确保使用直线引号,而不是通过文本编辑软件通常插入的卷曲引号。查看支持的标点符号。
本文转自:http://www.uisdc.com/amazon-voice-ux-design-2
